

azure Speech Serviceでテキスト化したものをAzure OpenAI自然言語処理(NLP)で解析し、Azure Logic Appsで通知を送る
1. ナレッジの整理と準備
目的
- 営業マンが必要とする情報(適切なアドバイスや回答)を明確にする。
- 会社独自のナレッジ(内部資料やFAQ)をテキスト化する。
タスク
- 営業トークスクリプト、不動産物件情報、顧客対応マニュアルを収集。
- PDFやWordファイルなどをテキストデータに変換。
- 不動産関連の一般的な知識と会社特有の知識を分類。
2. テキストデータの収集・前処理
目的
- モデルが効率よく学習・回答できるよう、データを整理する。
前処理手順
- データ形式の統一:
- テキストファイル、CSVなどの一貫性を保つ形式に変換。
- 不要な情報の削除:
- スペルミス、重複データ、無意味な記号を除去。
- 構造化データの作成:
- 以下のようにQAペアや命令データの形に変換。jsonコードをコピーする
{ "prompt": "住宅ローン控除の条件は?", "completion": "住宅ローン控除の条件は以下の通りです: 年収500万円以下、購入金額5000万円以下..." }
- 以下のようにQAペアや命令データの形に変換。jsonコードをコピーする
- トークン制限の確認:
- Azure OpenAI GPTモデルはトークン数の制限があるため、プロンプトと回答の長さを適切に制御。
3. Azure OpenAI Serviceのセットアップ
目的
AzureのGPTモデルを活用できる環境を構築する。
手順
- Azureポータルにサインイン:
- Azureアカウントを作成(未登録の場合)。
- Azure OpenAIリソースの作成:
- Azure Portalで「Azure OpenAI」を検索。
- 新しいリソースを作成し、適切なリージョンを選択。
- モデルのデプロイ:
- 使用するGPTモデル(例: GPT-3.5、GPT-4)を選択してデプロイ。
- エンドポイントとキーを取得:
- Azure Portalのリソースページから、エンドポイントURLとAPIキーを確認。
4. ナレッジベースのカスタマイズ
目的
カスタムナレッジをモデルが簡単に参照できるようにする。
手法
- Embedding(埋め込みベクトル): ナレッジをベクトル化して検索可能にする。
- テキストをベクトルに変換:
- Azure OpenAIの
text-embedding-ada-002モデルを使用して、テキストを数値化。 - Pythonコード例:pythonコードをコピーする
import openai openai.api_key = "YOUR_API_KEY" response = openai.Embedding.create( input=["住宅ローン控除について教えて"], model="text-embedding-ada-002" ) print(response['data'][0]['embedding'])
- Azure OpenAIの
- ベクトルデータの保存:
- ベクトルをデータベース(例: Pinecone、Weaviate)またはローカルストレージに保存。
- 検索システムの構築:
- 営業マンの質問をベクトル化し、保存済みのナレッジベースと類似度検索。
5. モデルの微調整(ファインチューニング)
目的
会社独自のナレッジをモデルに統合する。
手順
- トレーニングデータの作成:
- プロンプトと回答をペアにしたJSONL形式を準備。jsonコードをコピーする
{"prompt": "住宅ローンの審査基準は?", "completion": "住宅ローンの審査基準は、年収、勤続年数、借入額が含まれます。"}
- プロンプトと回答をペアにしたJSONL形式を準備。jsonコードをコピーする
- データをアップロード:
- Azure CLIまたはPython SDKを使用してデータをアップロード。
- 微調整の実行:
- Azure OpenAI APIを使ってカスタムモデルを作成。
- 微調整後のモデルをデプロイ。
6. APIの構築と統合
目的
営業マンが利用できる形でサービスを提供する。
手順
- Webまたはアプリとの統合:
- 営業マンが使用するツールにAPIを組み込み、リアルタイムで回答を提供。
- API設計:
- RESTful APIを設計し、Azure FunctionsやFlaskなどで実装。
7. 運用後の改善と評価
目的
システムの精度とユーザー体験を継続的に向上させる。
手順
- ユーザーフィードバックの収集:
- 提供した回答が適切だったかを評価するUIを用意。
- モデルの再学習:
- 新しいデータを定期的に収集し、モデルを更新。
- 性能モニタリング:
- Azure Monitorを利用してAPIの稼働状況を監視。
補足:機密性の確保
- データの暗号化:
- ナレッジベースのデータやトラフィックはすべて暗号化。
- アクセス制御:
- APIキーの管理、Azure Role-Based Access Control (RBAC)を使用。
- コンプライアンス:
- AzureはGDPRやISO 27001など主要な規制に準拠しているため、安心して利用可能。
ネットワークの設定
ネットワークの制限とセキュリティ向上:
- Zoomアプリが利用するAPIやバックエンドサービスを、社内ネットワーク内や特定のAzureリソース(例: プライベートエンドポイント)からのみアクセス可能に制限できます。
- Zoom SDKを活用したカスタムアプリを運用する場合に特に有効で、社内環境からのアクセスを安全に管理可能。
2. Zoom SDKを使用したカスタムアプリの運用
- Zoom SDKを利用してカスタムアプリを構築し、Azure上で運用する場合、関連サービスを VNet内で閉じた環境で構築 することでセキュリティを向上可能。
- 例: Zoom API経由でデータを処理するバックエンドをAzure FunctionsやVM上で動作させる。
- これを Azure Private Endpoint で接続すると、インターネットを経由せずに安全な通信が可能。
Zoom Video SDK設定方法
Zoom App SDK
• 目的:
• Zoomクライアントアプリ(Zoom MeetingやWebinarsなど)内で動作するアプリを構築するためのSDKです。
• Zoomクライアント内での「拡張機能」や「統合」を提供します。
Zoom Video SDK設定方法
認証
Zoom Video SDKは、セッションの開始および参加の認証にJSON Web Token(JWT)を使用します。
Video SDKアプリの認証情報を使用してVideo SDK JWTを生成してください。
あなたのVideo SDKアカウントのみがセッションを開始し、参加することができます。他のVideo SDKアカウントはあなたのアカウントのセッションに参加することはできません。また、Video SDKはZoomのミーティングやウェビナーには参加できません。
認証情報を取得する
Video SDK セッションに参加するための認証メカニズムである JSON Web Tokens (JWT) を作成するには、SDKキー および SDKシークレット を使用します。
開発者アカウントの作成または既存アカウントへのSDK追加
新しい開発者アカウントを作成するか、既存の Zoom Workplace アカウント にSDK製品を追加することができます。
1. Zoom Build プラットフォーム で新しい開発者アカウントを作成するか、Zoom Workplaceアカウントに Video SDK Pay As You Go または SDK Universal Credit を追加します。購入はこちらから可能です。
2. SDKアカウントウェブポータル にアクセスします。
• 新しい開発者アカウントを作成した場合は、ウェブポータルにサインインしてください。
• 既存のZoom WorkplaceアカウントにSDKプランを追加した場合は、ウェブポータルにサインインし、Advanced > Zoom CPaaS をクリックし、Universal Credit製品の横にある Manage をクリックします。SDKアカウントページが表示されます。
使用方法
Zoom Video SDKには2つの主要な使用方法があります:セッショントークン方式(現在の実装):セッション名は任意の文字列を使用可能同じセッション名とトークンを持つユーザー同士が接続できるトークンには特定のセッション名が紐付けられているZoom ミーティング連携方式:実際のZoomミーティングIDを使用Zoomミーティングと連携する場合は追加の設定が必要現在の実装は1番目の方式を使用しており:任意のセッション名(例:test123)を入力同じセッション名を使用する他のユーザーと接続実際のZoomミーティングとは独立した仕組み
azure
1. Azure Speech SDKのセットアップ
2. Zoom Video SDKでオーディオデータを取得
3. オーディオデータをリアルタイムでAzureに送信
4. Azureで会話を分析
5. 分析結果をZoomアプリに返す
音声ファイル形式
WAV (Waveform Audio File Format)
- 特徴: 無圧縮のオーディオフォーマットで、PCM(パルス符号変調)データを含みます。
- 用途: 高品質な音声を必要とするプロフェッショナルな録音や編集に使用されます。音質を最優先する場合に適しています。
- ファイルサイズ: 無圧縮のため、非常に大きい。
FLAC (Free Lossless Audio Codec)
- 特徴: ロスレス圧縮フォーマットで、音声品質を損なわずにファイルサイズを圧縮します。
- 用途: 音楽愛好者やアーカイブ用途に最適です。高音質を保ちながら、WAVよりも小さいファイルサイズを提供します。
- ファイルサイズ: WAVよりも小さいが、MP3やOGGよりは大きい。
MP3 (MPEG-1 Audio Layer 3)
- 特徴: 有損圧縮フォーマットで、音質の一部を犠牲にしてファイルサイズを大幅に削減します。
- 用途: 一般的な音楽再生やポッドキャストで広く使用されています。ファイルサイズを小さくすることで、ストレージや帯域幅を節約できます。
- ファイルサイズ: 非常に小さいが、音質は圧縮の度合いに依存。
OGG (Ogg Vorbis)
- 特徴: オープンソースの有損圧縮フォーマットで、MP3と競合する性能を持ちます。
- 用途: 高圧縮効率と柔軟性から、ゲームやデジタル音楽配信に使用されます。オープンソースなのでライセンス料が不要です。
- ファイルサイズ: MP3と同程度で、音質も同等かそれ以上。
RAW (Raw Audio Format)
- 特徴: 無圧縮の音声データで、メタデータやフォーマット情報を含みません。
- 用途: 音声データの解析や処理に使用されます。汎用性は高いですが、再生にはフォーマット情報が必要です。
- ファイルサイズ: 非常に大きい。
録画ファイルの保存
Electronを選んだ理由は、録画したファイルをローカルに保存する機能が求められているためです。WebRTCとMediaRecorder APIはブラウザ内で動作するため、直接ローカルファイルシステムにアクセスすることができません。Electronを使用することで、Node.jsのAPIを通じてファイルシステムにアクセスし、録画ファイルを保存することが可能になります。
コード分析 初期化プロセス (src/index.tsx):
// 1. URLパラメータの取得とdevConfigとのマージ
let meetingArgs = Object.fromEntries(new URLSearchParams(location.search));
if (!meetingArgs.sdkKey || !meetingArgs.topic || !meetingArgs.name) {
meetingArgs = { ...devConfig, ...meetingArgs };
}
// 2. 署名(JWT)の生成または設定
if (!meetingArgs.signature) {
meetingArgs.signature = devConfig.signature;
}
// 3. Zoomクライアントの作成
const zmClient = ZoomVideo.createClient();send_audio関数は音声ファイルを読み込み、必要に応じて再サンプリングし、チャンクに分けてAzureに送信
send_audio関数は音声ファイルを読み込み、必要に応じて再サンプリングし、チャンクに分けてAzureに送信IPC通信

現在の音声処理の流れを詳しく説明します:
- Zoom SDKからの音声取得(Recording.tsx):
// 1. Zoomの音声要素を取得
const audioElements = sessionContainer?.getElementsByTagName('audio');
// 2. 音声ストリームを取得
for (const audio of audioElements) {
if (audio.srcObject instanceof MediaStream) {
streams.push(audio.srcObject);
}
}
// 3. マイクからの音声も取得
const micStream = await navigator.mediaDevices.getUserMedia({ audio: true });
// 4. すべてのストリームを結合
const combinedStream = new MediaStream(tracks);- 音声処理(recording.ts):
// 1. AudioContextの設定(16kHzサンプリング)
this.audioContext = new AudioContext({ sampleRate: 16000 });
// 2. 音声ソースの作成
this.mediaStreamSource = this.audioContext.createMediaStreamSource(stream);
// 3. 音声処理ノードの作成(16384サンプルのバッファ)
this.processor = this.audioContext.createScriptProcessor(16384, 1, 1);
// 4. 音声レベルチェックと無音検出
const volume = Math.max(...audioData.map(Math.abs));
if (volume > silenceThreshold) {
// 5. Azure OpenAIに送信
await this.sendAudioToAzure(audioData);
});- Azure OpenAIへの送信(main.cjs):
// 1. 音声データをWhisperで文字起こし
const transcription = await client.getAudioTranscription(
process.env.AZURE_OPENAI_DEPLOYMENT,
Buffer.from(audioBuffer)
);
// 2. GPT-4で応答を生成
const response = await client.getChatCompletions(
process.env.AZURE_OPENAI_DEPLOYMENT,
messages
);リリース情報
Zoom WorkplaceプラットフォームでAI/MLワークロードに対応したメディアを簡単に利用できる新機能「Realtime Media Streams (RTMS)」のリリースが間もなく予定されています。
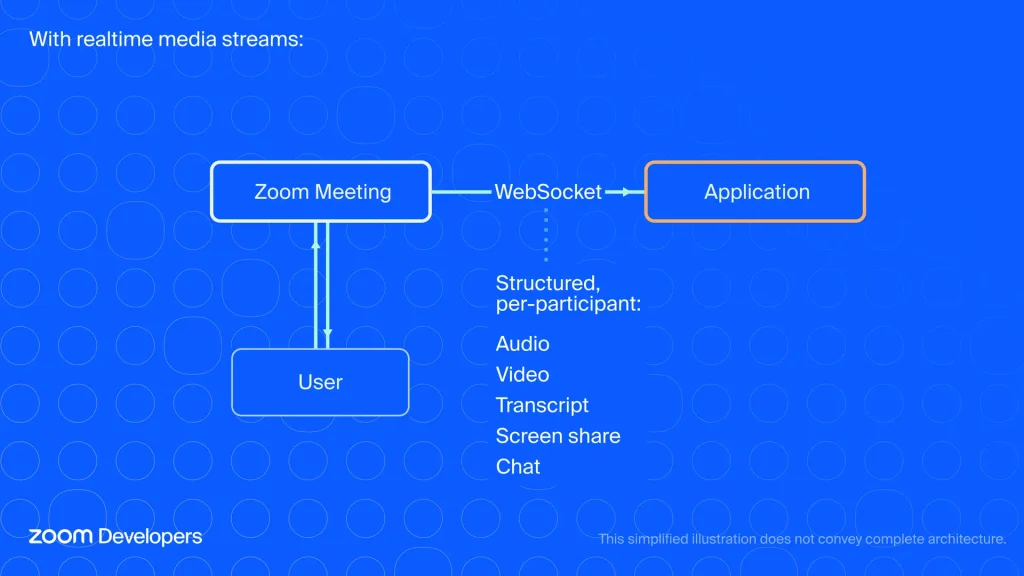
Realtime Media Streamsでは、音声、映像、文字起こし、チャット、画面共有などの参加者ごとのメディアストリームを、参加者用の「ボット」を使用せずに、WebSocketsを通じて取得できるようになります。
現在、Zoomミーティングでリアルタイムメディアにアクセスするには、参加タイミング、話者の特定、会話の終了時点などを理解するための複雑なビジネスロジックが必要であり、非常に手間とコストがかかります。
Realtime Media Streamsは、ミーティング内での自動化クライアント(ボット)の必要性を排除します。アプリケーションは、認可を受けたユーザーが利用できるコンテキストを反映した、参加者ごとの構造化されたデータストリームを直接受け取ることができます。
多くの開発者と話をする中で、現在のAIアプリ構築における複雑さと可能性について意見をいただきました。市場ごとに必要なものは大きく異なりますが、アクセスを得るための自動化クライアント管理の煩雑さが、共通の課題であることが分かっています。
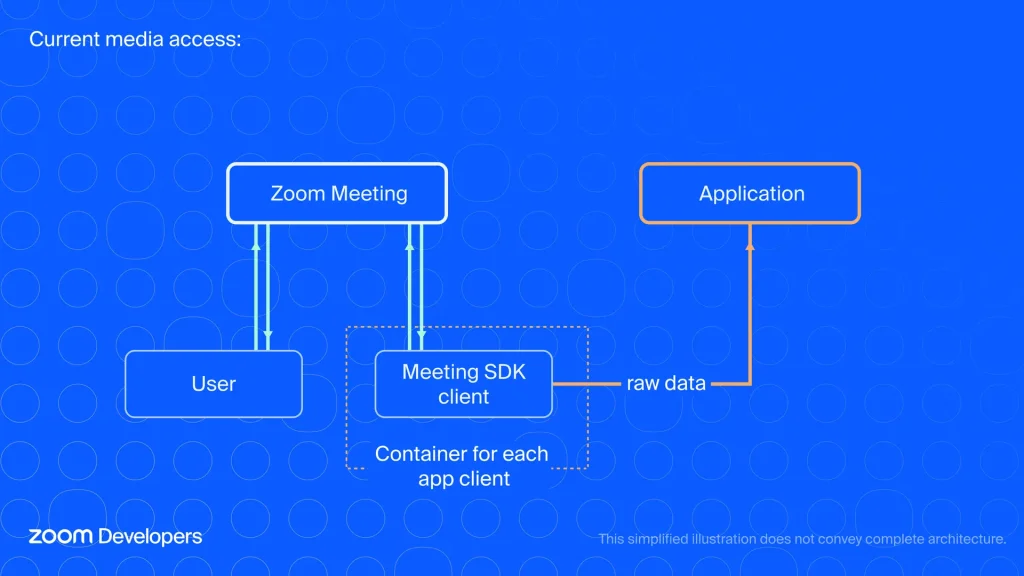
っf
アプリがユーザーとともに自動的に参加
Realtime Media Streams (RTMS) は、ユーザーの外部カレンダーと参加するミーティングや通話を調整するための複雑なビジネスロジックを簡略化します。
認証されたユーザーがミーティング、電話、コンタクトセンターでの対応、またはウェビナーに参加すると、アプリは選択されたメディアタイプで新しいストリームを受信します。これには、ホストやアカウント管理者による役割ベースのコントロールが適用されます。この仕組みにより、アプリは自動的なリスナーから、ユーザーに価値を提供することに集中できる受動的かつ深い統合を実現します。
アプリの理解と制御の向上
• RTMSアプリは、ミーティング中に参加者タイルとして表示されません。
• コンテンツにアクセスするアプリに新しい機能が提供され、特別に設計された同意フローにより、ホストや参加者がアプリのコントロールを行い、採用を促進します。
• ミーティング中の通知は、参加者にアプリが有効であること、そのアプリが何にアクセスしているか、誰がそのアプリを持ち込んだか、自分で使い始めるにはどうすればよいかを理解する手助けをします。
管理者向けの細かい制御
• 管理者は、アカウント全体でどのアプリが許可されるか、またどのデータ形式にアクセスできるかを管理するためのツールを使用できます。
• Realtime Media Streams は、アプリ開発者にとってより深いアクセスの選択肢を提供し、管理者やユーザーには管理と採用のためのコントロールを提供します。
コンテキストがすべて
Zoom Workplaceは、チームが意思決定を行い、顧客と関わり、アイデアをブレインストーミングする場です。このコンテキストは、AIアプリを実際に業務で役立つツールに変えるために極めて重要です。
私たちの目標は、開発者がAIアプリケーションを構築し、配布するための最も魅力的なプラットフォームを提供し、ユーザーや顧客にとって重要なコンテキストでこれらのアプリを活用できるようにすることです。



