

概要: /realtimeとは?
このプレビューでは、gpt-4o-realtime-previewモデルファミリーの新しい/realtime APIエンドポイントが紹介されています。/realtimeは以下の特徴を持ちます:
- 低遅延の「スピーチイン、スピーチアウト」会話インタラクションをサポート
- テキストメッセージ、関数呼び出し、その他のエンドポイントと同様に機能
- サポートエージェント、アシスタント、翻訳者など、高い応答性が必要なケースに最適
/realtimeの技術的概要
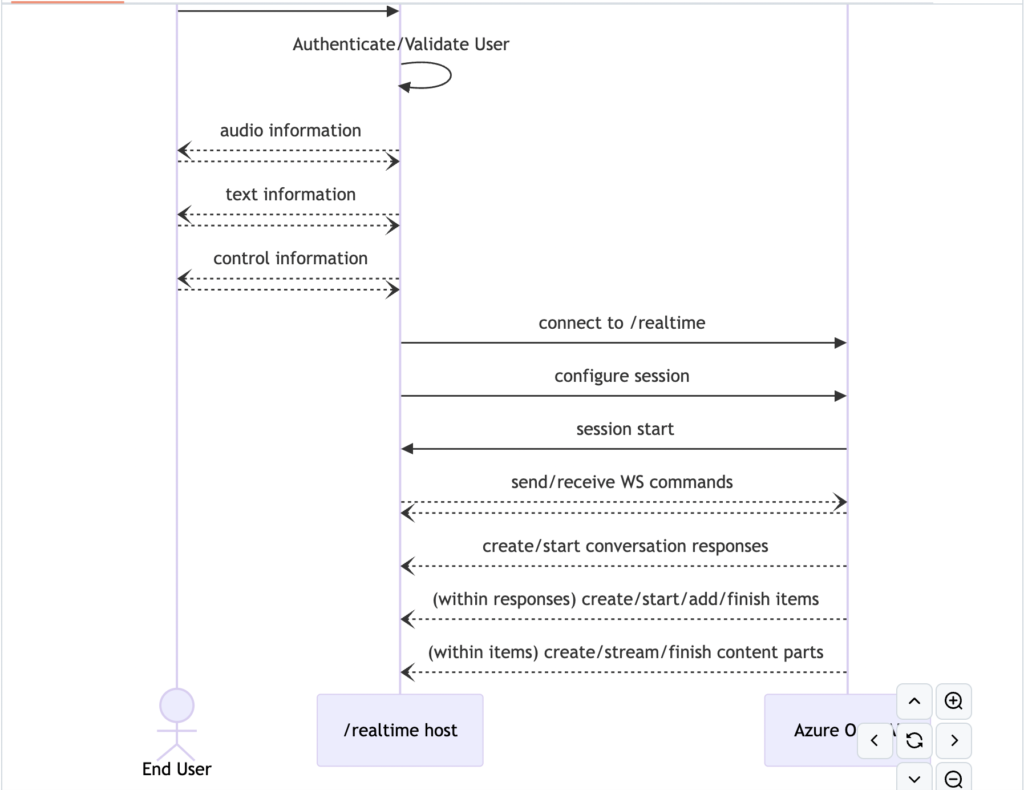
/realtimeはWebSockets APIを基盤としており、完全に非同期なストリーミング通信を提供します。信頼できる中間サービスでの使用が前提で、エンドユーザーのデバイスから直接使用することは想定されていません。
Azure OpenAI GPT-4処理:
音声データをテキストに変換→コンテキストを考慮した応答生成→ストリーミング形式でレスポンスを返送
処理の流れ
クライアント → サーバー(/realtime)
音声データがストリームとして送信される
サーバー → Azure OpenAI
まず音声認識(Whisper)で音声→テキスト変換
次にGPT-4でテキストの処理と応答生成
Azure OpenAI → サーバー → クライアント
生成された応答がストリーミングで返送される
始め方
- Azure OpenAIリソースの作成:
- eastus2またはswedencentralリージョンでリソースを作成します。
- gpt-4o-realtime-previewモデルのデプロイ:
- このモデル(2024-10-01バージョン)をサポートされたリソースにデプロイします。
- サンプルの利用:
- リポジトリに含まれるサンプルを使用して、/realtimeの機能を確認します。
接続と認証
/realtime APIは、サポートされているリージョン内の既存のAzure OpenAIリソースエンドポイントを必要とします。リクエストURIは以下の要素を連結して構築されます:
- 安全なWebSocket (wss://) プロトコル
- Azure OpenAIリソースエンドポイントのホスト名、例:
my-aoai-resource.openai.azure.com openai/realtimeAPIパス- サポートされているAPIバージョンのクエリ文字列パラメーター、例:
api-version=2024-10-01-preview - モデルデプロイメントの名前のクエリ文字列パラメーター
例: wss://my-eastus2-openai-resource.openai.azure.com/openai/realtime?api-version=2024-10-01-preview&deployment=gpt-4o-realtime-preview-1001
認証方法
- Microsoft Entraを使用:
- 適切に設定されたAzure OpenAIサービスリソースに対して、トークンベースの認証をサポート。Bearerトークンを使用します。
- APIキーを使用:
api-key接続ヘッダーまたはリクエストURIのクエリ文字列パラメーターとして提供できます。
API概念
- 呼び出し元は/realtimeに接続し、新しいセッションを開始します。
- セッションは音声の入力出力動作、音声活動検出の設定などをカスタマイズできます。
- セッションは自動的にデフォルトの会話を作成します。
これにより、高速で双方向な音声ベースの対話型アプリケーションを構築することができます。
アイテム管理
会話履歴の確立や音声以外の情報の含め方
conversation.item.create
- 会話に新しいアイテムを挿入します。previous_item_idに従って位置を指定できます。これにより、ユーザーからの新しい非音声入力(テキストメッセージなど)、ツールの応答、または他のインタラクションからの履歴情報を含めて、生成前の会話履歴を形成できます。
conversation.item.delete
- 既存の会話からアイテムを削除します。
conversation.item.truncate
- メッセージのテキストおよび/または音声コンテンツを手動で短縮します。リアルタイム生成が停止された場合に余分なデータが生成された状況で役立ちます。
応答管理
response.create
- 処理されていない会話入力のモデル処理を開始し、呼び出し元の論理的なターンの終了を示します。server_vad turn_detectionモードでは、音声の終了時に自動的に生成がトリガーされますが、他の状況(テキスト入力、ツールの応答、noneモードなど)では、会話が続行されることを示すためにresponse.createを呼び出す必要があります。
response.cancel
- 進行中の応答をキャンセルします。
応答フロー
response.created
- 会話の新しい応答が開始されたことを通知します。入力状態をスナップショットし、新しいアイテムの生成を開始します。response.doneが応答の終了を示すまで、response.output_item.addedによってアイテムを作成し、deltaコマンドで内容を提供します。
response.done
- 会話の応答生成が完了したことを通知します。
rate_limits.updated
- response.doneの直後に送信され、直前の応答消費後の最新のレート制限情報を提供します。
応答内のアイテムフロー
response.output_item.added
- 新しい、サーバー生成の会話アイテムが作成されていることを通知します。コンテンツはインクリメンタルなadd_contentメッセージとresponse.output_item.doneコマンドによって提供されます。
response.output_item.done
- 新しい会話アイテムが会話に追加されたことを通知します。
応答アイテム内のコンテンツフロー
response.content_part.added
- 継続中の応答で新しいコンテンツパートが会話アイテム内に作成されていることを通知します。response_content_part_doneが到着するまで、コンテンツは適切なdeltaコマンドでインクリメンタルに提供されます。
response.content_part.done
- 新しく作成されたコンテンツパートが完了し、これ以上のインクリメンタルな更新がないことを示します。
response.audio.delta
- モデルによって生成されたバイナリ音声データコンテンツパートのインクリメンタルな更新を提供します。
response.audio.done
- 音声コンテンツパートのインクリメンタルな更新が完了したことを示します。
response.audio_transcript.delta
- モデルによって生成された出力音声コンテンツに関連する音声転写のインクリメンタルな更新を提供します。
response.audio_transcript.done
- 出力音声の転写のインクリメンタルな更新が完了したことを示します。
response.text.delta
- 会話メッセージアイテム内のテキストコンテンツパートのインクリメンタルな更新を提供します。
response.text.done
- テキストコンテンツパートのインクリメンタルな更新が完了したことを示します。
response.function_call_arguments.delta
- 会話アイテム内の関数呼び出しの引数のインクリメンタルな更新を提供します。
response.function_call_arguments.done
- 関数呼び出しの引数のインクリメンタルな更新が完了し、蓄積された引数が完全に使用可能であることを示します。
ユーザー入力音声
input_audio_buffer.speech_started
- 設定された音声活動検出を使用すると、このコマンドは特定の音声サンプルインデックスでユーザーの音声が開始されたことを通知します。
input_audio_buffer.speech_stopped
- 設定された音声活動検出を使用すると、このコマンドは特定の音声サンプルインデックスでユーザーの音声が終了したことを通知します。設定に応じて、これにより応答生成が自動的にトリガーされます。
conversation.item.input_audio_transcription.completed
- ユーザーの入力音声バッファの補助転写が利用可能であることを通知します。この動作は、session.updateでinput_audio_transcriptionプロパティを通じてオプトインする必要があります。
conversation.item_input_audio_transcription.failed
- 入力音声の転写に失敗したことを通知します。
input_audio_buffer_committed
- ユーザー音声入力バッファの現在の状態が登録された会話に送信されたことを通知します。
input_audio_buffer_cleared
- 保留中のユーザー音声入力バッファがクリアされたことを通知します。
その他
error
- セッションでデータを処理中に問題が発生したことを示します。追加の詳細を提供するエラーメッセージを含みます。
トラブルシューティングとFAQ
ベストプラクティスと予想されるパターンは急速に進化しており、このセクションに表現されているトピックはすぐに時代遅れになる可能性があります。
音声を送信してもサービスからのコマンドが表示されない
- 入力音声フォーマットがsession.updateコマンドで提供されたもの(デフォルトでは24KHz、16ビットモノラルPCM)と一致していることを確認してください。フォーマットが一致しない場合、「ノイズ」としてデコードされ、入力として解釈されません。
- none turn_detectionモードを使用している場合、必要に応じてinput_audio_buffer.commitおよび/またはresponse.createコマンドを送信することを確認してください。
ツールの呼び出しが機能しない、または応答がない
- 単一の応答が複数のツールコールを特徴とする場合、ツールコール/応答契約で状態保持が導入されます。
- 呼び出し元は、item_addedメッセージが到着した後、ツールコール出力アイテムtool_callを追加できます。
- 現在の応答のすべてのアイテムが生成されると、モデルのresponse.doneコマンドが到着し、応答の一部であったすべてのツールコールおよびその他のアイテムへの参照を含みます。
- この時点で(すべての着信ツールコールが解決された後)、呼び出し元は新しいresponse.createコマンドを送信できます。
- 前の応答の対応するresponse.doneコマンドが到着する前にresponse.createコマンドを送信する(例:response.function_call_arguments.doneまたはresponse.output_item.done直後に)と、予期しない動作や競合状態が発生する可能性があります。
- response.createコマンドを送信しない場合、会話が進行しない可能性があります。
オーディオファイルを入力として使用すると、多くの応答が表示されたり、応答が停止したりする
- 長いオーディオ入力を使用する場合、リアルタイムよりもかなり高速に処理されるため、サーバーの音声活動検出が連続して多くの応答をトリガーし、信頼性が低下する可能性があります。このようなシナリオでは、音声活動検出を無効にし(session.updateで”turn_detection”: { “type”: “none” })、すべてのオーディオが送信された後に手動でresponse.createを呼び出すことを強くお勧めします。
README イントロダクション
このリポジトリには、リアルタイムAPIの利用を容易にするために設計されたカスタムクライアントを使用するサンプルコードが含まれています。含まれている主なサンプルは2つあります:
- low_level_sample.py: LowLevelClientを使用してAPIと対話します。
- client_sample.py: より高レベルなRTClientの使用を示します。RTClientは、APIの利用を簡素化するための抽象化レイヤーとして設計されています。
セットアップ手順
- 仮想環境の作成とアクティブ化 依存関係を適切に管理するために、仮想環境を使用することをお勧めします。以下の手順で仮想環境を設定してアクティブ化します:
bash
# 仮想環境の作成
python3 -m venv venv
# 仮想環境のアクティブ化
source venv/bin/activate- 依存関係のインストール 仮想環境がアクティブ化されたら、提供されたスクリプトを使用して最新のパッケージホイールをダウンロードし、pipを使用して必要な依存関係をインストールします:
- bashの場合:
download-wheel.shを使用このスクリプトを実行するには、jqがインストールされている必要があります。 - PowerShellの場合:
download-wheel.ps1を使用それぞれ./download-wheel.shまたはpwsh ./download-wheel.ps1と入力して実行します。
次に、依存関係をインストールします:
pip install -r requirements.txt
pip install rtclient-0.5.1-py3-none-any.whl- 環境変数の設定 このアプリケーションには、特定の環境変数を設定する必要があります。これらの変数は
.envファイルに定義できます。リポジトリにはdevelopment.envというテンプレートファイルが含まれています。以下の手順で.envファイルを設定します:
development.envテンプレートを新しいファイル.envにコピーします:bashcp development.env .env- テキストエディタで
.envファイルを開き、必要な値を入力します。テンプレートには必要な環境変数のプレースホルダーが含まれています。
- サンプルの実行 低レベルクライアントサンプルを実行するには:
python low_level_sample.py <audio file> <azure|openai><audio file>は実行時に使用する入力音声ファイルです(サポートされている形式のサンプルファイルがリポジトリに含まれています)。
ファイルの実行
client_sample.py (入力音声に対して応答するサンプルプログラム)
このプログラムを以下の引数で実行するとinput\arc-easy-q237-tts.flacというサンプル音声を使ってoutputフォルダに結果を出力します。
python .\client_sample.py .\input\arc-easy-q237-tts.flac output/ azure- 音声フォーマット設定:
sample_rate = 24000 # サンプリングレート
duration_ms = 100 # チャンクの長さ
bytes_per_sample = 2 # 16bitPCM
- 音声データの送信方法:
- RTClientを使用してWebSocket接続を確立
- 音声データを100msごとのチャンクに分割
client.send_audio(chunk)でバイナリデータとして送信
- サーバー設定:
await client.configure(
turn_detection=ServerVAD(
threshold=0.5,
prefix_padding_ms=300,
silence_duration_ms=200
),
input_audio_transcription=InputAudioTranscription(
model="whisper-1"
)
)確認すべきこと
REST APIベースの実装からWebSocketベースのストリーミング実装に移行する必要がある。
- Zoom SDKの音声取得
- DevToolsのコンソールで
[Recording] Found audio elements:のログを確認し、音声要素が見つかっているか確認 [Recording] Stream tracks:のログで、実際に取得できている音声トラックを確認
- 音声処理
[AudioProcessing] Current volume:のログで音声レベルを確認- 無音検出の閾値(現在0.01)が適切か確認
- サンプリングレート(16kHz)とバッファサイズ(16384サンプル)が適切か確認
- Azure OpenAIへの送信
[Azure] 音声データを送信中...のログでデータサイズを確認[Azure] 文字起こし結果:のログで文字起こしが成功しているか確認
javascript
Azure OpenAI /realtime: node-jsを使用したインタラクティブチャット
前提条件
- Node.jsのインストール (https://nodejs.org)
- localhostのウェブサーバーを実行できる環境
ライブラリパッケージの取得
これらのサンプルを動作させるためには、クライアントライブラリパッケージをこのフォルダにダウンロードする必要があります(または、ソースからビルドしてここにコピーすることもできます)。そのためのスクリプトをいくつか用意しています:
- bash用のdownload-pkg.sh > このスクリプトを実行するには
jqがインストールされている必要があります。 - PowerShell用のdownload-pkg.ps1
これらは、それぞれ./download-pkg.shまたはpwsh ./download-pkg.ps1と入力して実行できます。
./download-pkg.shサンプルの使用方法
- このフォルダに移動します
npm installを実行して、依存関係パッケージをダウンロードします(package.jsonを参照)npm run devを実行してウェブサーバーを起動し、ファイアウォール許可のプロンプトに従います- コンソール出力から提供されたURI(例:
http://localhost:5173/)をブラウザで開きます - 認証情報を追加します:Azure OpenAIを使用するには、
エンドポイントとAPIキーの両方が必要です。ここでは、Azure OpenAIリソースのエンドポイント(パスを含まない)を指定しますOpenAIに接続するには、エンドポイントは必要なく、APIキーのみを指定します - “Record”ボタンをクリックしてセッションを開始し、マイクの権限を許可します
- 左側の出力に
<< Session Started >>メッセージが表示された後、アプリに話しかけることができます - いつでも話しかけることでチャットを中断し、”Stop”ボタンを使用してチャットを完全に停止できます
- 必要に応じてシステムメッセージ(例:”You always talk like a friendly pirate”)やカスタム温度を指定できます。これらは次回のセッション開始時に反映されます
既知の問題
- 接続エラーはまだ優雅に処理されておらず、スクリプトのデバッグ出力にエラーループが表示される場合があります。エラーが表示された場合は、ウェブページをリフレッシュしてください。
- 音声選択はまだサポートされていません。
- Entraによるキーレスサポートなど、より多くの認証メカニズムが将来のサービスアップデートで提供される予定です。
コード説明
このサンプルでは、リアルタイムAPIの使用を簡素化するためのカスタムクライアントを使用しています。クライアントパッケージは、ライブラリをビルドするか、提供されたスクリプトを使用してダウンロードすることで取得できます:
- bash – このスクリプトを実行するには
jqがインストールされている必要があります。 - PowerShell
/realtimeの使用を示す主要なファイルはsrc/main.tsです。最初のいくつかの関数は、クライアントを使用して/realtimeに接続し、推論構成メッセージを送信し、接続でのメッセージ送受信を処理する方法を示しています。




